
The Search Dilemma - Part 1
Have you ever thought what if a search engine (like Google, Bing or Yahoo) took hours to answer your search queries? Well, neither do I. But I presume that most people would be angry and just stop using them. This assumption is corroborated by a 2009 study[R1] that revealed that a delay of 2 seconds in delivering search results may impact companies’ revenue in over 4% per user; in other words, slow answers equals to less cash flow.
Big companies have many ways to address this (quality-of-service) issue and make this response time faster: the most obvious of them is simply deploying faster processors, more memory caches and upgrading network speed for distributed computing. However, this approach is not really the most efficient as there are financial (deploying more servers cost money) and spatial (your datacenter has limited space) constraints. Jeff Dean[R2] shows some manners to circumvent these constraints and maximize the system’s efficiency while guaranteeing the same quality-of-service for all users. I’ll discuss one of them here.
First of all, what is ‘search’? On the user perspective, it’s possible to define it as being the process where for a given ‘kw’ keyword - with variable length l - we obtain a ranked set of ‘S’ answers from our search-engine database; the set of keywords may be also known as ‘query’. From the given definition, we can infer that a search engine has 3 different applications that act concurrently: the one who searches for new content (known as crawling), the one who make this content readable for our engine (indexing) and the one who scores the content according to our interest (ranking). For more technical details, Larry Page’s paper[R3] (Anatomy of a Search Engine) goes way further in explaining those processes.
In most of the cases, ranking is the serviceable application for users, and their perception of the service may heavily depend on how faster or slow ranking is both computed and returned as a result. As a corollary, optimizing computational resources usage for maximum efficiency while maintaining a consistent quality of service is economically critical for server operators. However, having only powerful processors at the datacenter is not enough, as it is empirically shown by [R4] and Figure 1 that the relationship between energy consumption and the related number of operations per second is nearly exponential.
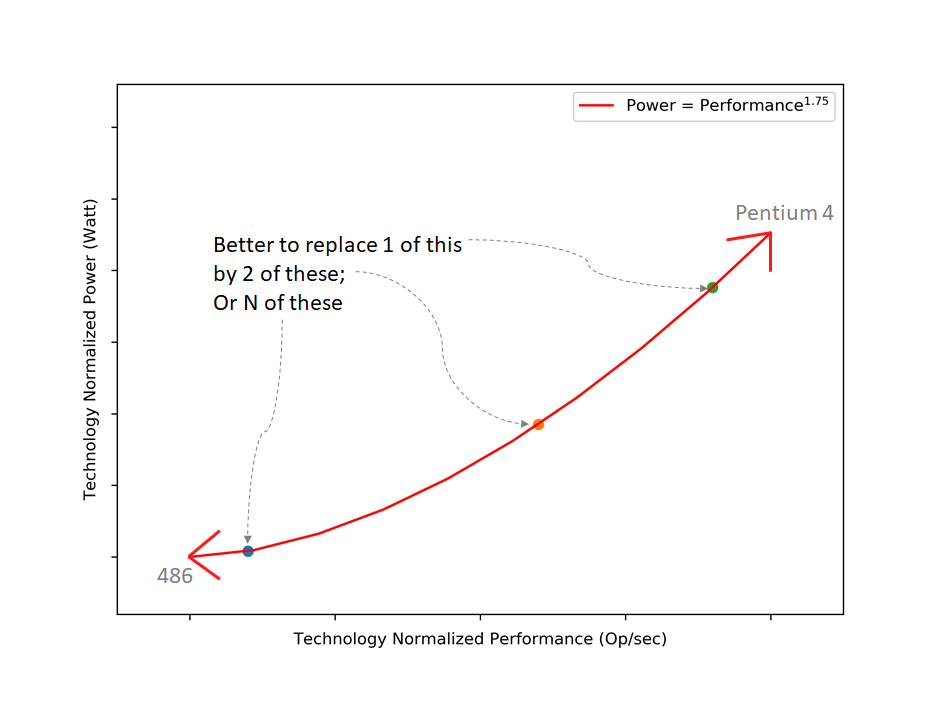
Now, let’s assume that we have two types of systems: the brawn-core systems and the wimpy-core systems, where the former has a high single-core performance while the latter is more power-efficient and has lower single-core performance. Let’s also assume that, for stochastic reasons, not all queries are equal. With those assumptions, the conclusion that different queries take different times to be processed is also reasonable. That’s the root of our efficiency problem.
If we set a soft deadline of 2000 milliseconds, as proposed by the study described at the beginning of this text, we’ll notice that part of those queries may take longer processing time than 2000 milliseconds on the wimpy-core systems, while significantly less time on the brawny-core systems - which is pretty safe to assume. So, if we can detect which queries will take longer than our defined deadline and move then to a brawny-core, we (i) improve the quality-of-service, as the user-sent request will not break the deadline, and (ii) also improve energy efficiency as we’ll optimize our resource usage.
Let’s prove this.
First, we need to empirically show that the assumption that some queries may take a longer processing time than others. So, by using an ARM Juno board, which uses the big.LITTLE[N1] technology, we started our experiments with the Elasticsearch[N2] application. We indexed part of the Wikipedia (about ~20gb of data) and wrote a load generator so it can send different requests - and we sent exactly 200.000 for each processor type. First, we ran only on “big” cores and then only “little” cores, and we let Elasticsearch do all the default scheduling. Figure 2 shows the cumulative distribution function for the response time.
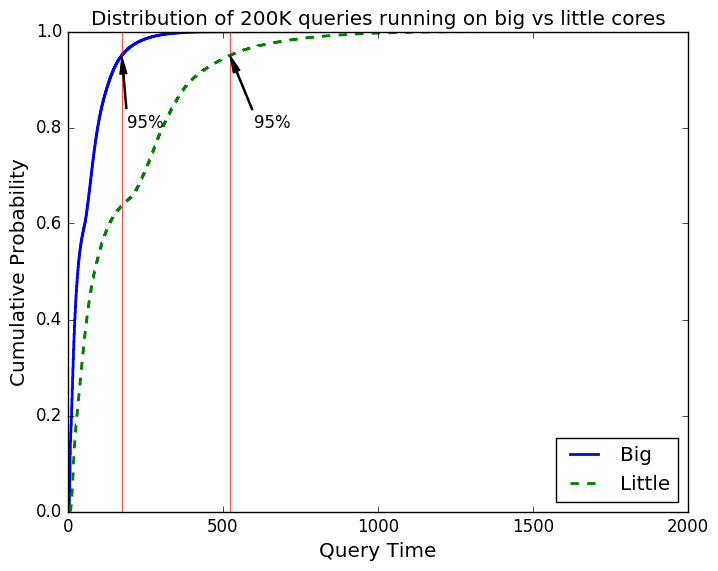
Two conclusions can be easily taken from the above graph: first, that the actual architecture of the processor does matter - hence, the queries on ‘big’ tend to run faster than on ‘little’ cores. Second, that not all search queries are equal - there must be a determining factor that makes some take longer than others.
The most obvious factor? The size of the search. We ran another experiment with only small keywords length (from 1 to 4 words) and another with longer keywords lengths (from 11 to 15) and the difference is statistically significant (believe me, I ran the tests two years ago). Figure 3 shows the results.
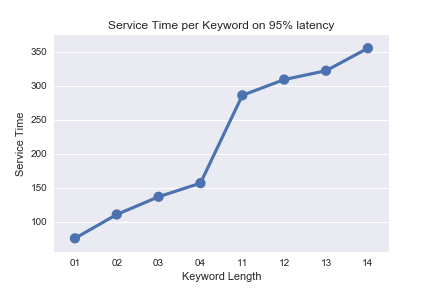
Hence, there’s a correlation between longer keywords and energy consumption - since the former will be processing for a longer time, the latter goes up. If we are able to detect which requests are comprised of longer keywords, we’ll be able to also reduce our energy problem.
The Part 2 of this series will be related to my own solution for this problem, which is more about software profiling and instrumenting. Hope to see you there!
Author’s note: This was part of the work I did during my master’s degree. Except when referenced, graphs and results were created by me. Please do not use any of the content listed here without my explicit consent.
Notes:
[N1] In a nutshell, big.LITTLE technology is simply a processor with two different architectures: the big one is computationally faster, however uses way more energy than its little counterpart - which is slower, but more energy-efficient. Task scheduling is done by the Linux kernel through an algorithm known as “Global Task Scheduling”, which uses an statistical model to allocate threads into the big or little cores.
[N2] Elasticsearch is a software written in Java that works as a search engine: it indexes, searches and scores the results.
References:
[R1] The User and Business Impact of Server Delays, Additional Bytes, and HTTP Chunking in Web Search, a conference by Eric Schurman and Jake Brutlag.
[R2] Tail at Scale, an article by Jeff Dean.
[R3] The anatomy of a large-scale hypertextual Web search engine, by Sergey Brin and Lawrence Page.
[R4] Energy per Instruction Trends in Intel Microprocessors, a (white) paper by Ed Grochowski and Murali Annavaram.